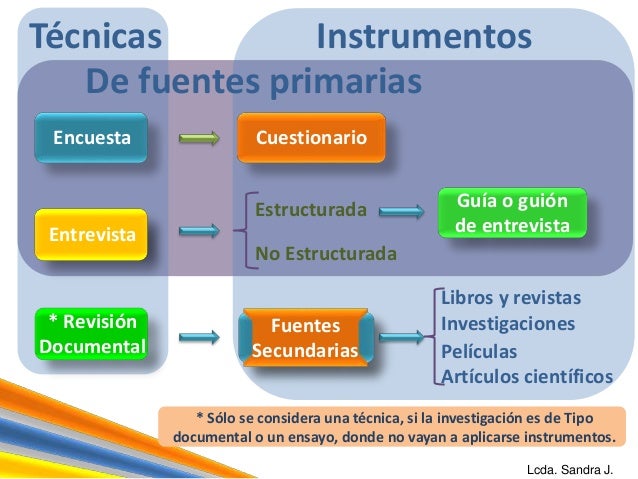
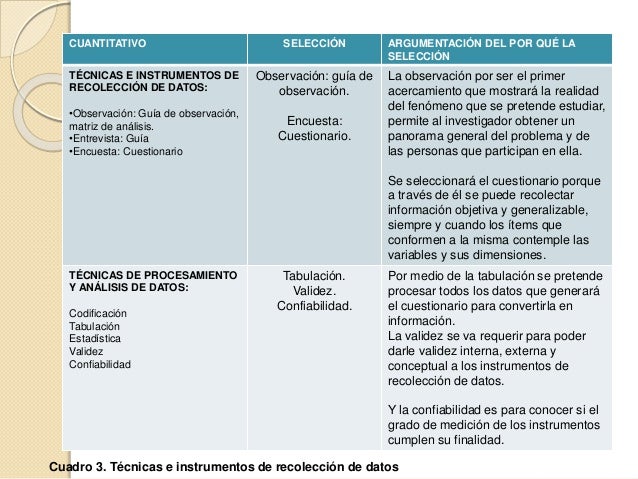
Una vez recogida, registrada y organizada la información del trabajo de campo, procede ahora ver si nuestros planteamientos teóricos son soportados con los datos empíricos. Esto se realiza mediante dos tareas íntimamente ligadas: el análisis y la interpretación de resultados.
El análisis consiste básicamente en dar respuesta a los objetivos o hipótesis planteados a partir de las mediciones efectuadas y los datos resultantes. Para plantear el análisis es conveniente plantear un plan de análisis o lo que se conoce como un plan de explotación de datos. En él se suele detallar de manera flexible cómo vamos a proceder al enfrentarnos a los datos, cuáles serán las principales líneas de análisis, qué orden vamos a seguir, y qué tipo de pruebas o técnicas de análisis aplicaremos sobre los datos.
La interpretación, a diferencia del análisis, tiene un componente más intelectual y una función explicativa. Su misión es buscar un significado al resultado del análisis mediante su relación con todo aquello que conocemos sobre el problema, de manera que aportamos una significación sociológica a los hallazgos encontrados en el análisis, confirmando, modificando o realizando nuevos aportes a la teoría previa sobre ese problema.
1- ¿Qué es estadística?
Es una ciencia referente a la recolección, análisis e interpretación de datos, ya sea para ayudar en la resolución de la toma de decisiones o para explicar condiciones regulares o irregulares de algún fenómeno o estudio aplicado, de ocurrencia en forma aleatoria o condicional.
Un estudio estadístico consta de las siguientes fases:
- Recogida de datos.
- Organización y representación de datos.
- Análisis de datos.
- Obtención de conclusiones.
2- ¿Cómo se divide la estadística?
La estadística se divide en dos elementos:
2.1- Estadística descriptiva
Se dedica a los métodos de recolección, descripción, visualización y resumen de datos originados a partir de los fenómenos en estudio.
2.2- Estadística inferencial
Se dedica a la generación de los modelos, inferencias y predicciones asociadas a los fenómenos en cuestión teniendo en cuenta la aleatoriedad de las observaciones. Se usa para modelar patrones en los datos y extraer inferencias acerca de la población bajo estudio.
3- Conceptos de estadística
- Población:
Una población es el conjunto de todos los elementos a los que se somete a un estudio estadístico.
- Individuo:
Un individuo o unidad estadística es cada uno de los elementos que componen la población.
- Muestra:
Una muestra es un conjunto representativo de la población de referencia, el número de individuos de una muestra es menor que el de la población.
- Muestreo:
El muestreo es la reunión de datos que se desea estudiar, obtenidos de una proporción reducida y representativa de la población.
- Valor:
Un valor es cada uno de los distintos resultados que se pueden obtener en un estudio estadístico. Si lanzamos una moneda al aire 5 veces obtenemos dos valores: cara y cruz.
- Dato:
Un dato es cada uno de los valores que se ha obtenido al realizar un estudio estadístico. Si lanzamos una moneda al aire 5 veces obtenemos 5 datos: cara, cara, cruz, cara, cruz.
4- Variable estadística
- Definición de variable
Una variable estadística es cada una de las características o cualidades que poseen los individuos de una población.
4.1- Tipos de variable estadísticas
a) Variable cualitativa
Las variables cualitativas se refieren a características o cualidades que no pueden ser medidas con números. Podemos distinguir dos tipos:
- Variable cualitativa nominal:
Una variable cualitativa nominal presenta modalidades no numéricas que no admiten un criterio de orden.
Por ejemplo:
- El estado civil, con las siguientes modalidades: soltero, casado, separado, divorciado y viudo.
- Variable cualitativa ordinal o variable cuasi-cuantitativa:
Una variable cualitativa ordinal presenta modalidades no numéricas, en las que existe un orden.
Por ejemplo:
- La nota en un examen: suspenso, aprobado, notable, sobresaliente.
- Puesto conseguido en una prueba deportiva: 1º, 2º, 3º, ...
- Medallas de una prueba deportiva: oro, plata, bronce.
b) Variable cuantitativa
Una variable cuantitativa es la que se expresa mediante un número, por tanto se pueden realizar operaciones aritméticas con ella. Podemos distinguir dos tipos:
- Variable discreta
Una variable discreta es aquella que toma valores aislados, es decir no admite valores intermedios entre dos valores específicos.
Por ejemplo:
El número de hermanos de 5 amigos: 2, 1, 0, 1, 3.
- Variable continua
Una variable continua es aquella que puede tomar valores comprendidos entre dos números.
Por ejemplo:
- La altura de los 5 amigos: 1.73, 1.82, 1.77, 1.69, 1.75.
En la práctica medimos la altura con dos decimales, pero también se podría dar con tres decimales.
Distribución de frecuencias
Ir a la navegaciónIr a la búsqueda
En estadística, se le llama distribución de frecuencias a la agrupación de datos en categorías mutuamente excluyentes que indican el número de observaciones en cada categoría.1 Esto proporciona un valor añadido a la agrupación de datos. La distribución de frecuencias presenta las observaciones clasificadas de modo que se pueda ver el número existente en cada clase.Tipos de frecuencias
Frecuencia completa
La frecuencia completa por su denominación es el número de veces que aparece un determinado valor en un valor estadístico. Se representa por fila. La suma de la frecuencia completa es igual al número total de datos, que se representa por N. Para indicar resumidamente estas sumas se utiliza la letra griega Σ (sigma mayúscula) que se lee sumatoria.
Frecuencia relativa
Se dice que la frecuencia relativa es el cociente entre la frecuencia absoluta de un determinado valor y el número total de datos. Se puede expresar en tantos por ciento y se representa por hi. La suma de las frecuencias relativas es igual a 1
Frecuencia relativa (hi) es el cociente entre la frecuencia absoluta y el tamaño de la muestra (N). Es decir:

siendo el fi para todo el conjunto i. Se presenta en una tabla o nube de puntos en una distribución de frecuencias.
Si multiplicamos la frecuencia relativa por 100 obtendremos el porcentaje o tanto por ciento (pi).
Frecuencia acumulada
La frecuencia acumulada es la suma de las frecuencias absolutas de todos los valores inferiores o iguales al valor considerado.
La frecuencia acumulada es la frecuencia estadística F(XXr) con que el valor de un variable aleatoria (X) es menor que o igual a un valor de referencia (Xr).
La frecuencia acumulada relativa se deja escribir como Fc(X≤Xr), o en breve(Xr), y se calcula de
Fc (Hr) = HXr / N
donde MXr es el número de datos X con un valor menor que o igual a Xr, y N es número total de los datos. En breve se escribe:
Fc = M / N
Cuando Xr=Xmin, donde Xmin es el valor mínimo observado, se ve que Fc=1/N, porque M=1. Por otro lado, cuando Xr=Xmax, donde Xmax es el valor máximo observado, se ve que Fc=1, porque M=N.
En porcentaje la ecuación es:
Fc(%) = 100 M / N
Frecuencia relativa acumulada
La frecuencia relativa acumulada es el cociente entre la frecuencia acumulada de un determinado valor y el número total de datos. Se puede expresar en tantos por ciento. Ejemplo:
Durante el mes de julio, en una ciudad se han registrado las siguientes temperaturas máximas:
32, 31, 28, 29, 33, 32, 31, 30, 31, 31, 27, 44
Distribución de frecuencias agrupadas
La distribución de frecuencias agrupadas o tabla con datos agrupados se emplea si las variables toman un número grande de valores o la variable es continua. Se agrupan los valores en intervalos que tengan la misma amplitud denominados clases. A cada clase se le asigna su frecuencia correspondiente. Límites de la clase. Cada clase está delimitada por el límite inferior de la clase y el límite superior de la clase.
La amplitud de la clase es la diferencia entre el límite superior e inferior de la clase. La marca de clase es el punto medio de cada intervalo y es el valor que representa a todo el intervalo para el cálculo de algunos parámetros. En caso de que el primer intervalo sea de la forma (-∞,k], o bien [k,+∞) donde k es un número cualquiera, en el caso de (-∞,k], para calcular la marca de clase se tomará la amplitud del intervalo adyacente a el (ai+1), y la marca de clase será ((k-ai+1) +k)/2. En el caso del intervalo [k,+∞) también se tomará la amplitud del intervalo adyacente a el (ai-1) siendo la marca de clase ((k+ai-1)+k)/2.
Construcción de una tabla de datos agrupados:
3, 15, 24, 28, 33, 35, 38, 42, 43, 38, 36, 34, 29, 25, 17, 7, 34, 36, 39, 44, 31, 26, 20, 11, 13, 22, 27, 47, 39, 37, 34, 32, 35, 28, 38, 41, 48, 15, 32, 13.
- Se localizan los valores menor y mayor de la distribución. En este caso son 3 y 48.
- Se restan y se busca un número entero un poco mayor que la diferencia y que sea divisible por el número de intervalos que queramos establecer.
Es conveniente que el número de intervalos oscile entre 6 y 15.
En este caso, 48 - 3 = 45, incrementamos el número hasta 50 : 5 = 10 intervalos.
Se forman los intervalos teniendo presente que el límite inferior de una clase pertenece al intervalo, pero el límite superior no pertenece al intervalo, se cuenta en el siguiente intervalo.
| Intervalo | ci | ni | Ni | fi | Fi |
|---|
| [0, 5) | 2.5 | 1 | 1 | 0.025 | 0.025 |
| [5, 10) | 7.5 | 1 | 2 | 0.025 | 0.050 |
| [10, 15) | 12.5 | 3 | 5 | 0.075 | 0.125 |
| [15, 20) | 17.5 | 3 | 8 | 0.075 | 0.200 |
| [20, 25) | 22.5 | 3 | 11 | 0.075 | 0.275 |
| [25, 30) | 27.5 | 6 | 17 | 0.150 | 0.425 |
| [30, 35) | 32.5 | 7 | 24 | 0.175 | 0.600 |
| [35, 40) | 37.5 | 10 | 34 | 0.250 | 0.850 |
| [40, 45) | 42.5 | 4 | 38 | 0.100 | 0.950 |
| [45, 50) | 47.5 | 2 | 40 | 0.050 | 1 |
| Total: | | 40 | | 1 | |
https://www.tdx.cat/bitstream/handle/10803/8917/CapituloIVAnalisisdelosResultados.pdf?sequence=5&isAllowed=y
Media, moda, mediana, rango
Octavo básico - Actividad Nº 790
1- Media aritmética
Es la suma de todos los datos dividida entre el número total de datos. Se calculan dependiendo de cómo vengan ordenados los datos.
Ejemplo:
¿Cuál es la media de las edades de Andrea y sus primos?
La media aritmética de un grupo de datos se calcula así:
Se debe multiplicar cada dato con su respectiva frecuencia, sumar todos estos productos, y el resultado dividirlo por la suma de los datos.
Ejemplo:
Se ha anotado el número de hermanos que tiene un grupo de amigos. Los datos obtenidos son los siguientes:
Hermanos: 1, 1, 1, 1, 2, 2, 2, 3, 3, 4
Si hacemos el recuento de los datos y seguimos los pasos anteriormente descritos, tenemos:
2- Moda
La moda de un conjunto de datos es el dato que más veces se repite, es decir, aquel que tiene mayor frecuencia absoluta. Se denota por Mo. En caso de existir dos valores de la variable que tengan la mayor frecuencia absoluta, habría dos modas. Si no se repite ningún valor, no existe moda.
- Ejemplo1:
¿Cuál es el dato que más se repite en el ejemplo anterior?
El dato que más se repite es el 1, es el que tiene mayor frecuencia absoluta (4 veces).
La moda del número de hermanos es 1
- Ejemplo 2:
2, 3, 4, 5 , 6 , 9
En este conjunto de datos no existe ningún valor que se repita, por lo tanto, este conjunto de valores no tiene moda.
- Ejemplo 3:
1, 1, 1, 4, 4, 5, 5, 5, 7, 8, 9, 9, 9 Mo= 1, 5, 9
Si en un grupo hay dos o varias puntuaciones con la misma frecuencia y esa frecuencia es la máxima, la distribución es bimodal o multimodal, es decir, tiene varias modas.
- Ejemplo 4:
0, 1, 3, 3, 5, 5, 7, 8 Mo = 4
Si dos puntuaciones adyacentes tienen la frecuencia máxima, la moda es el promedio de las dos puntuaciones adyacentes.
3- La mediana
La mediana es el valor que ocupa el lugar central entre todos los valores del conjunto de datos, cuando estos están ordenados en forma creciente o decreciente.
La mediana se representa por Me.
Calculo de la mediana:
1° Ordenamos los datos de menor a mayor.
- La mediana de un conjunto con un número impar de datos es, una vez ordenados los datos, el dato que ocupa el lugar central.
Ejemplo:
Calcular la mediana del conjunto de datos:
- También podemos usar la siguiente fórmula para determinar la posición del dato central:
(n + 1) /2 = mediana datos impares.
- La mediana de un conjunto con un número par de datos es, una vez ordenados, la media de los dos datos centrales.
Ejemplo:
Calcular la mediana del conjunto de datos:
4- Rango
El rango da la idea de proximidad de los datos a la media. Se calcula restando el dato menor al dato mayor.
Este dato permite obtener una idea de la dispersión de los datos, cuanto mayor es el rango, más dispersos están los datos de un conjunto.
Ejemplo:
Se preguntó a 9 familias cuántas bicicletas tenían en total, dieron las respuestas ordenadas en la siguiente tabla:
- ¿Cómo hallarías el rango?
Se resta el dato mayor al dato menor: 3 - 0 = 3; Por lo tanto el rango sería 3 en este caso.
Si el conjunto de datos que se recolecta es muy numeroso, o bien, si el rango es muy amplio, es conveniente agruparlos y ordenarlos en intervalos o clases.
La amplitud o tamaño de cada intervalo se puede calcular dividiendo el valor del rango por la cantidad de intervalos que se desean obtener.
4- Ejercicios:
1- Se le pregunta a un grupo de personas acerca de la cantidad de libros que leyó durante el año 2015, y las respuestas son: 4; 3; 2; 7; 10; 8; 2; 9; 3; 6; 8; 1; 1; 9; 2. La moda de la muestra es:
a) 2 b) 3 c) 4 d) 5 e) 9
2- Halla la mediana de las siguientes series estadísticas.
a) 1, 7, 3, 2, 4, 6, 2, 5, 6
b) 4, 2, 1, 3, 8, 5, 3, 1, 6, 7
3- Se tienen dos distribuciones cuyos datos son los siguientes:
Distribución A: 9, 5, 3, 2, 1, 2, 6, 4, 9, 8, 1, 3, 5, 4, 2, 6, 3, 2, 5, 6, 7
Distribución B: 1, 1, 3, 2, 5, 6, 7, 2, 5, 4, 3, 1, 2, 1, 5, 7, 8, 9, 9, 2, 1
a) Halla el rango de ambas distribuciones.
4- Se tiene el siguiente conjunto de datos:
10, 13, 4, 7, 8, 11, 10, 16, 18, 12, 3, 6, 9, 9, 4, 13, 20, 7, 5, 10, 17, 10, 16, 14, 8, 18
a) Obtén la mediana
Respuestas:
1- a
2- a) 1, 2, 2, 3, 4, 5, 6, 6, 7 M = 4
b) 1, 1, 2, 3, 3, 4, 5, 6, 7, 8; La mediana es la media aritmética de los dos valores centrales, M = 3,5.
3- Rango de A: 9 - 1 = 8
Rango de B: 9 - 1 = 8
4- a) Ordenamos los datos de menor a mayor:
3, 4, 4, 5, 6, 7, 7, 8, 8, 9, 9, 10, 10, 10, 10, 11, 12, 13, 13, 14, 16, 16, 17, 18, 18, 20
Como hay 26 valores, la mediana es la media de los dos valores centrales: M= 10 + 10 / 2 = 10
Interpretación de tablas de frecuencias
Octavo básico - Actividad Nº 786
1- Interpretación de tablas de frecuencias
Una tabla de frecuencias resume la información acerca de la cantidad de veces que una variable toma un valor determinado. Además permite Organizar e interpretar de manera más rápida y eficiente.
1.1- La frecuencia absoluta
Corresponde a la cantidad de veces que se repite un dato. Denotamos este valor por fi.
La suma de las frecuencias absolutas es igual al número total de datos, que se representa por N.
Por Ejemplo:
Si hacemos una encuesta a 20 personas para saber cuál es su color favorito obtenemos lo siguiente:
[Tabla 1]

1.2- La Frecuencia Absoluta Acumulada
Se obtiene sumando sucesivamente las frecuencias absolutas. Denotamos este valor por Fi.
[Tabla 2]
1.3- La Frecuencia Relativa
Es la probabilidad de obtener cierto dato, se obtiene calculando la razón entre la frecuencia absoluta de un dato con el total. Se puede expresar como fracción, decimal o porcentaje. Denotamos este valor por hi.
[Tabla3]

Para obtener el numero en decimal se divide la frecuencia absoluta por el total y para obtener el porcentaje se multiplica este decimal por 100.
Los ejemplos representan una tabla de frecuencias de datos No agrupados, en el caso de las tablas de datos Agrupados representan las frecuencias en rangos de datos, como en el siguiente caso.
Se entrevistan a 28 personas que realizan un taller preguntándoles la edad que tengan:
[tabla 4]
1.4- Frecuencia relativa acumulada
La frecuencia relativa acumulada es el cociente entre la frecuencia acumulada de un determinado valor y el número total de datos. Se puede expresar en tantos por ciento. Denotamos este valor por Hi
Se calcula:
Fi /N
Gráficos estadísticos
Primero medio - Actividad N° 50
1- Gráficos estadísticos
Existe una gran cantidad de gráficos para la representación de datos estadísticos, entre los principales tenemos:
a) Gráfico de Barras
El gráfico de barras, como su nombre lo indica, está constituido por barras rectangulares de igual ancho, conservando la misma distancia de separación entre sí. Se utiliza básicamente para mostrar y comparar frecuencias de variables cuantitativas o comportamientos en el tiempo, cuando el número de ítems es reducido.
Para elaborarlo debemos:
- Utilizar un sistema de coordenadas rectangulares y se llevan al eje de las "x" los valores que toma la variable en estudio y en el eje de las "y" se colocan las frecuencias de cada barra.
- Luego se construyen los rectángulos, tomando como base al eje de las abscisas, cuya altura será igual a cada una de las diferentes frecuencias que presentan las variables en estudio.
- La magnitud con que viene expresada la variable se observa en la longitud de las barras (rectángulos). Es importante destacar que solamente la longitud de las barras y no su anchura es lo que denota la diferencia de magnitud entre los valores de la variable.
Todas las barras tienen que tener una anchura igual, separadas entre sí, preferiblemente por una longitud igual a la mitad del ancho de estas o distancias iguales entre barras.
Las barras se pueden graficar tanto verticalmente como horizontalmente. Se pueden elaborar barras compuestas y barras agrupadas.

Este tipo de gráfico se clasifican por:
- Barras simples: Compara valores entre categorías de una variable
- Barras dobles: Compara valores entre categorías de dos variables
- Barras múltiples: Compara valores entre categorías de dos o más variables.
- Barras verticales: Las categorías de la variable deben ubicarse en el eje x.
- Barras horizontales: Las categorías de la variable deben ubicarse en el eje y.
- Barras Aplicadas: Compara entre categorías el aporte de cada valor en el total.
b) Gráfico de sectores Circulares:
Usualmente llamado gráfico de torta, debido a su forma característica de una circunferencia dividida en sectores, por medio de radios que dan la sensación de un pastel cortado en porciones.
Se usa para representar variables cualitativas en porcentajes o cifras absolutas cuando el número de ítems no es superior a 5 y se quiere resaltar uno de ellos.
c) Gráfico de líneas o Tendencia:
Usado básicamente para mostrar el comportamiento de una variable cuantitativa a través del tiempo. El gráfico de líneas consiste en segmentos rectilíneos unidos entre sí, los cuales resaltan las variaciones de la variable por unidad de tiempo.
Cuando se tienen varias variables a representar, con el fin de establecer comparaciones entre ellas (siempre que su unidad de medida sea la misma); se utiliza plasmarlos en un solo gráfico, el cual es el resultado de representar varias variables en un mismo plano. A este tipo de gráfico se le llama gráfico de líneas compuesto.
Criterios para elaborar un gráfico de líneas:
1- La utilización de la escala que se utilizará en el plano cartesiano puede variar tomando en cuenta el fenómeno que se va a graficar. No es necesario que las abscisas (ejes x) y las ordenadas (eje y) del plano cartesiano lleven la misma escala; sin embargo, cuando las magnitudes de las variables no se diferencian sustancialmente es recomendable utilizar escalas iguales para obtener un gráfico con mayor precisión.
2- Cuando una de las variables en estudio se inicia con valores muy altos es recomendable no comenzar el eje por el origen cartesiano sino por un valor próximo o por el mismo valor por donde comienza la variable.
3- Es costumbre representar en el eje de las x del plano cartesiano la variable independiente del estudio que se realiza y en el eje de las y la variable dependiente.
En aquellos casos que se dificulta distinguir el tipo de variable se recomienda colocar en la ordenada del plano cartesiano las frecuencias de las variables en estudio y sobre la abscisa la variable cronológica (años, semanas, días, horas, etc.)
d) Histograma de frecuencias:
El histograma es un diagrama en forma de columna, muy parecido a los gráficos de barras. Se define como un conjunto de rectángulos paralelos, en el que la base representa la clase de la distribución y su altura la magnitud que alcanza la frecuencia de la clase correspondiente. Son barras rectangulares levantadas sobre el eje de las abscisas del plano cartesiano utilizando escalas adecuadas para los valores que asume la variable en la distribución de frecuencia.
El ancho de la base de los rectángulos es proporcional a cada clase de la distribución, de tal manera que, cuando la distribución tiene clases de igual tamaño, el tamaño de todos los rectángulos tendrá bases iguales.
Los lados del rectángulo se levantan sobre los puntos del eje de las x que corresponden a los límites de cada clase y la longitud de los mismos será igual a la frecuencia que tenga esa clase, los lados por lo tanto corresponden a la frecuencia de cada clase de la distribución de frecuencia.
Cuando se elaboran gráficas estadísticas en el plano cartesiano es recomendable que en el eje de las ordenadas se representen las frecuencias y el eje de abscisas las variables independientes.
e) Polígono de frecuencias:
Se utiliza básicamente para mostrar la distribución de frecuencias de variables
cuantitativas. Para construir el polígono de frecuencia se toma la marca de clase
que coincide con el punto medio de cada rectángulo de un histograma.
Pasos para elaborar un polígono de frecuencias:
1- Se dibuja un plano cartesiano.
2- Se traza sobre el eje de las abscisas, a distancias iguales, los puntos medios de las diferentes
clases de la distribución de frecuencias.
3- Se levantan perpendiculares por cada una de las marcas de clase, con una
longitud igual a la
frecuencia de cada una de las clases que integran la distribución de frecuencia. Al
final de cada perpendicular se marca un punto.
4- Los puntos resultantes se unen por medio de una línea recta obteniéndose una
línea poligonal.
5- Con la finalidad de cerrar la línea poligonal se agrega una clase imaginaria con
frecuencia
cero a cada extremo de la distribución de frecuencia, por tal motivos ambos extremos
del polígono se cortan con el eje de las abscisas.
También se puede elaborar un polígono de frecuencia después de haber graficado
un histograma; si se determina el punto medio de cada rectángulo de un histograma
y esos puntos medios se unen por medio de segmentos de recta dan como resultado el polígono
de frecuencia.
f) Histograma de frecuencias acumuladas:
Se utiliza básicamente para mostrar la distribución de frecuencias acumulada de
variables cuantitativas. Es una gráfica que se elabora con los valores de las
frecuencias acumuladas (menor que y mayor que) y los límites de las clases de una
distribución de frecuencia. El polígono de frecuencia acumulada se le conoce
comúnmente como ojiva.
La ojiva es una representación gráfica que consiste en una línea, que puede ser
ascendente o descendente y se utiliza para representar las distribuciones de
frecuencias acumuladas menor que y mayor que, según los datos utilizados. En los
estudios de análisis estadísticos la ojiva es de gran utilidad porque permite obtener
con gran aproximación cierta información requerida, en un momento determinado.
mas informacion en los siguientes enlaces:
El análisis estadístico es un componente del análisis de datos. En el contexto de la inteligencia de negocios (BI), el análisis estadístico requiere recoger y escudriñar cada muestra de datos individual en una serie de artículos desde los cuales se puede extraer las muestras.
El análisis estadístico puede ser dividido en cinco pasos discretos, de la siguiente manera:
- Describir la naturaleza de los datos a ser analizados.
- Explorar la relación de los datos con la población subyacente.
- Crear un modelo para resumir la comprensión de cómo los datos se relacionan con la población subyacente.
- Probar (o refutar) la validez del modelo.
- Emplear el análisis predictivo para ejecutar escenarios que ayudarán a orientar las acciones futuras.
El objetivo del análisis estadístico es identificar tendencias. Un negocio de venta al por menor, por ejemplo, podría utilizar el análisis estadístico para encontrar patrones en los datos no estructurados y semi-estructurados de los clientes que se puedan utilizar para crear una experiencia para el cliente más positiva y aumentar las ventas.
mas informacion en los sigientes enlaces
PREPARACIÓN DE UN ESTUDIO ESTADÍSTICO
Preparación de un estudio estadístico
Las probabilidades de que tu profesor de probabilidades y estadística te pida
un proyecto de recolección de datos son altas. No te preocupes, nosotros
te ayudaremos con eso.
Este tipo de proyectos, generalmente, sigue el mismo patrón. A continuación,
te dejamos los pasos que debes seguir:
- Haz una pregunta.
- Crea una hipótesis.
- Recolecta los datos.
- Analiza los datos.
- Plantea los datos.
- Llega a una conclusión.
¿Cómo se hace una buena pregunta?
Para comenzar, debes tener un buen "tema" para preguntar. Elige algo que
te interese. Puedes realizar preguntas de seguimiento para desarrollar
completamente tu proyecto. También deberás saber qué tipo de datos vas a
recolectar. Por ejemplo: ¿Serán datos numéricos o serán respuestas con
palabras? ¿Necesitarás ambas?
A continuación, te damos algunos ejemplos de buenas preguntas para
estudios estadísticos:
a) ¿La opinión política de los padres influye en la posición política de los estudiantes en la secundaria de Shmoople Hills?
b) Los estudiantes de 8vo grado de mi escuela,
¿deberían tener menos tareas?
¿Por qué son buenas preguntas las anteriores?
a) Porque son interesantes.
b) Porque están orientadas específicamente hacia un público en
particular.
Ejemplos de preguntas no tan buenas para estudios estadísticos:
a) ¿Nadar es más popular que el hockey sobre hielo?
b) ¿Quiénes son más altos, los chicos o las chicas?
¿Por qué las preguntas anteriores no son tan buenas? Si no especficas el
grupo que vas a medir, todo se complica ¿Quieres comparar a todos los
chicos y las chicas del mundo? Eso puede llegar a ser realmente complicado.
Además, en general, las comparaciones de popularidad no revelan ninguna
correlación interesante en los estudios estadísticos.
Después de elegir el tema, necesitarás diseñar las preguntas específicas. Las
buenas preguntas son imparciales, es decir, que no tratarán de influenciar a
la persona encuestada hacia una respuesta en particular. Digamos que
quieres reducir la cantidad de tarea que los profesores asignan y haces las
siguientes preguntas:
a) En promedio, ¿cuánto tiempo pasas cada noche haciendo la tarea?
b) Muchos chicos están preocupados porque no tienen suficiente
tiempo libre ¿estás de acuerdo?
¿Qué pregunta es parcializada, a ó b? Si respondiste b, es probable que
estés prestando atención. La pregunta b influye al entrevistado para que esté
de acuerdo con tu punto de vista. Las mejores preguntas son concisas,
específicas, directas y neutrales (no influyen).
Preparación de un estudio de muestra
Shmoop quiere saber cómo los estudiantes de San Francisco usan dos redes
sociales ficticias llamadas FaceSpace y MyBook.
Para hacerlo más interesante (que no sea un simple sondeo de popularidad),
queremos ver si hay diferencias en la forma en que los chicos y chicas
responden a las preguntas de nuestra encuesta.
En nuestra encuesta de mentira, les preguntamos a 50 chicos y a 50 chicas
de una escuela media, las siguientes preguntas:
- ¿Usas FaceSpace, MyBook o ambos?
- ¿Cuánto tiempo al día le dedicas a estas páginas?
- ¿Tienes "agregados" a tus padres?
- ¿Sabes si tus padres monitorean el uso que les das a estas páginas?
También puedes crear un cuestionario de fácil uso que puede ser rellenado
con las respuestas tanto por el entrevistador como por el entrevistado.
Nuestro cuestionario ficticio fue una tabla parecida a la que verás a
continuación (para las chicas). Para los chicos hicimos una parecida.
| Niñas | MyBook (s/n) | FaceSpace (s/n) | Tiempo (horas) | ¿Tus padres están agregados a tus amigos? (s/n) | ¿Tus padres te monitorean? (s/n) |
| 1 | | | | | |
| 2 | | | | | |
| 3 | | | | | |
| 4 | | | | | |
| 5 | | | | | |
| 6 | | | | | |
| 7 | | | | | |
| 8 | | | | | |
Al usar esta tabla podemos rápidamente escribir las respuestas de cada
entrevistado.
Formulación de una hipótesis
Ahora que sabes qué vas a estudiar, debes predecir qué demostrarán tus
resultados. Esto se llama formulación de hipótesis; adivinar cómo resultarían
las generalizaciones y por qué serían de esa manera.
Para nuestro estudio, esperamos encontrar que las chicas usen más MyBook
y FaceSpace y dediquen más tiempo a estas páginas que los chicos.
Además, creemos que los padres estarán más inclinados a monitorear a sus
hijas que a sus hijos.
Recolección de muestras
Estás a punto de recolectar tus datos, pero lee esta parte con mucho cuidado
antes de continuar. Para llevar a cabo un estudio preciso, es importante saber
a quiénes entrevistarás. Lo más seguro es que no puedas encuestar a toda
la población que te interesa estudiar, sino que tendrás que tomar solo una
muestra de esa población. No podemos preguntarles a todos los estudiantes
de las escuelas medias del mundo sus hábitos en las redes sociales, así que
elegimos una muestra de 50 chicas y 50 chicos.
La muestra tiene que ser elegida de forma aleatoria para que el resultado sea
estadísticamente significativo. Si quieres saber cuál es la película favorita
de los estudiantes en tu escuela media y les preguntas a tus amigos, no
estarías tomando una muestra representativa de todos los estudiantes, ya
que tus amigos probablemente compartan los mismos intereses y gustos.
Aun cuando te pares fuera del salón de ciencias y les hagas las preguntas a
los primeros 30 chicos que salgan, esa tampoco sería una muestra aleatoria.
Es probable que les preguntes a los de tu mismo grado y seguramente
quienes responderán serán también amigos tuyos.
A continuación, mira algunas formas de obtener una muestra realmente
aleatoria en tu escuela:
- Escribe los nombres de todos los estudiantes en papelitos, mételos en
- una caja y aleatoriamente (como una lotería) saca papelitos.
- Coloca un cuestionario en cada quinto locker de tu escuela.
- Elige aleatoriamente a 10 profesores y pídeles que pasen el cuestionario a sus alumnos.
Análisis de resultados
Ahora que has diseñado un estudio, creado un cuestionario y encuestado a
una muestra aleatoria, es momento de ver los números, sumar, restar,
multiplicar y dividir. El primer paso es simplemente sumar los números de tu
encuesta. Luego, calcula el porcentaje para cada categoría
y ponlos en una tabla.
Imaginemos que este fue el resultado de nuestro estudio de las redes
sociales, como si en realidad hubiéramos entrevistado a 50 chicas y 50
chicos de escuelas media en San
Francisco.
Resultados de redes sociales (% que respondió
sí a las preguntas) | Chicas | Chicos |
| MyBook | 86% | 66% |
| FaceSpace | 30% | 36% |
| Ambos | 24% | 22% |
| Ninguno | 8% | 20% |
| Padres "agregados" a amigos | 66% | 50% |
| Monitoreados por sus padres | 54% | 30% |
| Promedio de tiempo que pasa en estas páginas | 2.20 hr/día | 1.01 hr/día |
Aunque sean solo los porcentajes básicos, igual indican una tendencia.
Basado en nuestra encuesta de mentira, las chicas pasan significativamente
más tiempo en las redes sociales que los chicos, y los padres tienden a
monitorear a sus hijas más que a sus hijos
|